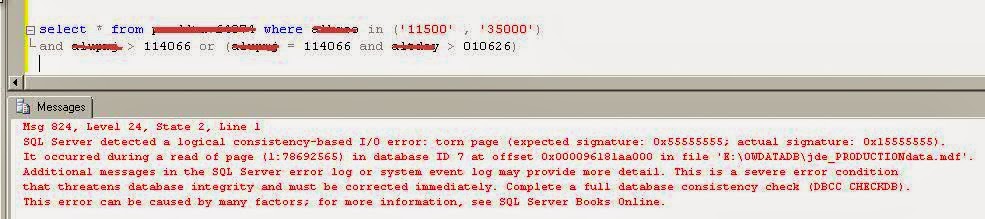
Yeah Corruption. A term that we won't like to hear in a production environment. Unfortunately I not only heard, but faced it. I would rather state myself being lucky enough to work on a corruption issue.
It started with an email from the Customer stating that one of their reports got failed with an error.
"jdbodbc.C5583 [Microsoft][SQL Server Native Client 10.0][SQL Server]Could not continue scan with NOLOCK due to data movement. - SQLSTATE: 37000"
It normally occurs in 2 scenarios.
1) While running a query with NOLOCK hint and Isolation level for the transaction is READ-UNCOMMITTED
2) Database Corruption
I quickly verified that the transaction isoaltion level was READ-COMMITTED. Then I decieded to run the query (query that is being used by the report ) both with and without NOLOCK hint and I got the following errors.
WITH NOLOCK Hint
==============
Error 601: Could not continue scan with NOLOCK due to data movement

WITHOUT NOLOCK Hint
===============
Msg 824, Level 24, State 2
It was a bit hard to digest that I was dealing with a corruption issue and understood the fact that the coming days are gonna be busy for me. But I was ready for that. We arranged the call with customer and explained the seriousness of issue and mentioned the urgency in running DBCC CHECKDB as early as possible without which it would be difficult to understand the depth and number of objects(Tables/Pages) affected.
Then arises the question from customer regarding the time frame required for running CHECKDB.
Any Ideas ???
There are a lot of factors that is depended on it. I would like to summarize a few in simple way I can.
- Size of Database
- IO Load on the server and its throughput ability
- Concurrent activities on CPU
- Concurrent Updates to Database (Ideal to be in Single User Mode)
- Number of CPU's and the Tempdb
- Complexity of Database Schema
- Number of Corruptions and type
Hence I would simply say the best way to estimate the time required for CHECKDB is to Run it. But we can estimate based on some references. I would like to provide my environment specifications which may help you to give an estimate.
My environment configurations are as follows.
Size of Database :- 1 TB
CPU's :- 2
Corruption Details :- UNKNOWN
DB Schema :- 1 Clustered Index
To estimate the TEMPDB space requirements, I ran the DBCC command as mentioned below.
DBCC CHECDB('DBname') WITH ESTIMATEONLY
But I would say that this is a very Wrong estimate and readers please beware of this.
It says maximum of only 2GB required for the operation but the reality was that it was close to 20/22 GB for my 1TB database. Later I found from Paul Randal's Blog that its a
BUG.
We started running the CHECKDB on QA to estimate the time required and based on that we ran it on Production after planning all pre-checks like drive space where tempdb resides etc. It ran for 10 hours and returned with 12 errors with 2 system object errors.
To summarise the ETA for DBCC CHECKDB for a 1 TB with 2 CPU's will be approximately 10-11 hours.
Results of CHECKDB
================
"Msg 8909, Level 16, State 1, Line 1
Table error: Object ID 0, index ID -1, partition ID 0, alloc unit ID 0 (type Unknown), page ID (1:78692566) contains an incorrect page ID in its page header. The PageId in the page header = (0:0).
Msg 8909, Level 16, State 1, Line 1
Table error: Object ID 0, index ID -1, partition ID 0, alloc unit ID 0 (type Unknown), page ID (1:78692567) contains an incorrect page ID in its page header. The PageId in the page header = (0:0).
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
DBCC results for 'table_name'.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78264522) is missing a reference from previous page (1:78692565). Possible chain linkage problem.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78264524) is missing a reference from previous page (1:78692567). Possible chain linkage problem.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692565) could not be processed. See other errors for details.
Msg 8939, Level 16, State 98, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data), page (1:78692565). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 29493257 and -1.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692565) was not seen in the scan although its parent (1:78137174) and previous (1:78264521) refer to it. Check any previous errors.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692566) could not be processed. See other errors for details.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692566) was not seen in the scan although its parent (1:78137174) and previous (1:78264522) refer to it. Check any previous errors.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692567) could not be processed. See other errors for details.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692567) was not seen in the scan although its parent (1:78137174) and previous (1:78264523) refer to it. Check any previous errors.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:82809613) is missing a reference from previous page (1:78692566). Possible chain linkage problem.
There are 50427099 rows in 2393300 pages for object "Table_name".
CHECKDB found 0 allocation errors and 10 consistency errors in table 'Table_name' (object ID 2098926649).
CHECKDB found 0 allocation errors and 12 consistency errors in database 'DB_name'.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (DB_Name).
So we are in the middle of system object corruption(cannot be repaired) and started preparing for Recovery Plans and procedures.
Plan 1
========
The basic plan set in place was restoring from the backups. But it was a very long process as we had to start with a Good Clean Full backup followed by application of T-logs. We started the restoration activity and realized the issue that I explained in one of my previous post(VM backup and LSN chain break). So literally Plan 1 got failed.
Plan 2
=========
Create an SSIS package for "
TRANSFER SQL SERVER OBJECTS" task and transfer everything except the corrupted table. For corrupted table manually do traversal with help of TOP N in ascending and descending Order by clustered Index key and thus retrieve maximum rows. We planned this activity on QA and started first part of this Plan2. It took around 66 hours, and was a NO GO from client side as it required that much downtime in production.
But since System Objects also had the corruption, Microsoft also suggested same when we raised the Case for this Issue. But whatever ways, loss of data was sure.
Since data loss was for sure, I started thinking about doing a Repair using CHECKDB. This thought helped me create a Plan 3
Plan3
========
Take a latest backup of Production database and restore it with "
Continue_after_error" option as there are chances that the restore may fail because of corruption. Once restored successfully, take the row count of all tables. Make the DB into Single user mode. Run the command
DBCC CHECKDB('database_name',REPAIR_ALLOW_DATA_LOSS)
Once repair is completed verify the dbcc log and take a row count and compare. Please find few highlighted results of our CHECKDB Repair...
Msg 8909, Level 16, State 1, Line 1
Table error: Object ID 0, index ID -1, partition ID 0, alloc unit ID 0 (type Unknown), page ID (1:78692566) contains an incorrect page ID in its page header. The PageId in the page header = (0:0).
The error has been repaired.
Msg 8909, Level 16, State 1, Line 1
Table error: Object ID 0, index ID -1, partition ID 0, alloc unit ID 0 (type Unknown), page ID (1:78692567) contains an incorrect page ID in its page header. The PageId in the page header = (0:0).
The error has been repaired.
CHECKDB found 0 allocation errors and 2 consistency errors not associated with any single object.
CHECKDB fixed 0 allocation errors and 2 consistency errors not associated with any single object.
DBCC results for 'Table_Name'.
==========================
Repair: The Clustered index successfully rebuilt for the object "table_name" in database "Database_Name".
Repair: The page (1:78692565) has been deallocated from object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data).
Repair: The page (1:78692566) has been deallocated from object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data).
Repair: The page (1:78692567) has been deallocated from object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data).
Msg 8945, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1 will be rebuilt.
The error has been repaired.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78264522) is missing a reference from previous page (1:78692565). Possible chain linkage problem.
The error has been repaired.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78264524) is missing a reference from previous page (1:78692567). Possible chain linkage problem.
The error has been repaired.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692565) could not be processed. See other errors for details.
The error has been repaired.
Msg 8939, Level 16, State 98, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data), page (1:78692565). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 29362185 and -1.
The error has been repaired.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692565) was not seen in the scan although its parent (1:78137174) and previous (1:78264521) refer to it. Check any previous errors.
The error has been repaired.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692566) could not be processed. See other errors for details.
The error has been repaired.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692566) was not seen in the scan although its parent (1:78137174) and previous (1:78264522) refer to it. Check any previous errors.
The error has been repaired.
Msg 8928, Level 16, State 1, Line 1
Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data): Page (1:78692567) could not be processed. See other errors for details.
The error has been repaired.
Msg 8976, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:78692567) was not seen in the scan although its parent (1:78137174) and previous (1:78264523) refer to it. Check any previous errors.
The error has been repaired.
Msg 8978, Level 16, State 1, Line 1
Table error: Object ID 2098926649, index ID 1, partition ID 419030233579520, alloc unit ID 419030233579520 (type In-row data). Page (1:82809613) is missing a reference from previous page (1:78692566). Possible chain linkage problem.
The error has been repaired.
There are 50932994 rows in 2417291 pages for object "table_name".
CHECKDB found 0 allocation errors and 10 consistency errors in table 'table_name' (object ID 2098926649).
CHECKDB fixed 0 allocation errors and 10 consistency errors in table 'table_name' (object ID 2098926649).
Final Comment
=============
CHECKDB found 0 allocation errors and 12 consistency errors in database 'DB Name'.
CHECKDB fixed 0 allocation errors and 12 consistency errors in database 'DB Name'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
After Row comparison, it was just 22 rows that were missing and the Customer was too happy and was ok with that result.
Note
=====
We tested this on QA with a backup of Production before implementing it on Production.
Thus the Issue was resolved with a simple plan. I had spend 40 days for this issue...Hope this post would help at least some DBA not to spend huge amount of time as I did, since I have already mentioned 3 plans in this post.
Enjoy and have a gr8 Day ahead !!!
Cheers
Jinu